


此前我们在macOS 内核之系统如何启动?提到内核作为一个巨大的 Mach-O 文件如何被加载到内存运行的,不过内核是被 BootLoader(iBoot) 加载的,入口 LC_UNIXTHREAD 也是 ASLR 应用之前的旧实现。
那么内核是如何运行起一个 App 的呢?
〇、背景知识
在开始之前我们先了解几个简单的背景知识:XNU 的 Process (进程)的组成是怎样的?
我们知道 Process 这个抽象概念是指一个 Program (程序)加上它所持有的 Resources (资源)。资源包括物理的 CPU 时间和内存,或者抽象的文件概念等等。
我们知道 XNU 内核主要由 BSD 和 Mach 两个部分组成,BSD 作为 Unix 内核提供了 Unix Process,Mach 内核则把 Process 抽象为 Task 和 Thread,所以在 macOS 上,一个进程既是 Mach Task 也是 BSD Process。不过内核中比较多的 IPC 是通过 Mach 来完成的。
Mach Task 的定义在 osfmk/kern/task.h,这个结构体非常大,持有 IPC space, memory address space, Mach threads, BSD info 等非常多进程相关信息。
我们在用户空间给自己的 App 新起线程的时候,无论是用 NSThread 还是其他上层接口,系统都用 pthread 接口实现了(POSIX Threads)。进入到内核空间,一个 pthread 对应的是一个 Mach Thread,结构体定义在 osfmk/kern/thread.h,就是 struct thread。机器相关的定义在 struct machine_thread,不同的架构各有一个实现。thread 带有 struct task *task; 信息指向对应的进程。这个 Mach Thread 里也包含了 BSD 的 uthread。
所以一个 pthread 既是 Mach thread 也是 Unix thread。所以内核在创建一个新进程的时候,就需要同时创建 Unix Process 和 Mach Task,以及他们需要的 threads, processors 等各种信息。
0.1 内核是有进程数上限设定的
我们可以通过 sysctl 查看:
➜ sysctl -a | grep -i proc
kern.maxproc: 4176
内核也在 bsd/conf/param.c hardcoded 了数字 NPROC:
#if CONFIG_EMBEDDED
#define NPROC 1000 /* Account for TOTAL_CORPSES_ALLOWED by making this slightly lower than we can. */
#define NPROC_PER_UID 950
#else
#define NPROC (20 + 16 * 32)
#define NPROC_PER_UID (NPROC/2)
#endif
/* NOTE: maxproc and hard_maxproc values are subject to device specific scaling in bsd_scale_setup */
#define HNPROC 2500 /* based on thread_max */
int maxproc = NPROC;
一、传统 Unix 方法 fork() 与 exec()
在传统的 Unix 系统中,fork() 是唯一用来创建新进程的方法,该方法将复刻一个当前进程的完整结构,包括二进制代码。所以负责启动其他 App 的进程为了能跑其他人的程序,还需要配合 exec() 方法,把 fork 出来的进程的 image 覆盖成新 App 的。
macOS 的 BSD 部分也提供了 fork() 方法,返回值是 pid_t,为 0 即表示当前跑在子进程,-1 是失败,其他就是父进程的 pid。参考 MTU 课程的一个示例代码:
#include <stdio.h>
#include <sys/types.h>
#define MAX_COUNT 200
void ChildProcess(void); /* child process prototype */
void ParentProcess(void); /* parent process prototype */
void main(void)
{
pid_t pid;
pid = fork();
if (pid == 0)
ChildProcess();
else
ParentProcess();
}
void ChildProcess(void)
{
int i;
for (i = 1; i <= MAX_COUNT; i++)
printf(" This line is from child, value = %d\n", i);
printf(" *** Child process is done ***\n");
}
void ParentProcess(void)
{
int i;
for (i = 1; i <= MAX_COUNT; i++)
printf("This line is from parent, value = %d\n", i);
printf("*** Parent is done ***\n");
}
BSD 提供的 exec() 方法有很多,可以参考这里:
execl, execlp, execle, exect, execv, execvp, execvP -- execute a file
但最终都会进入 execve() 系统调用,这是内核提供给用户空间用于打开其他程序的唯一接口。
1.1 fork()
1.1.1 用户空间的准备工作
在进入内核实现之前,fork() 在用户空间还做了一大堆事情,这些是在 libSystem 里面实现的,源码可以在这里找到。
我们的示例代码在调用 fork() 函数之后,就会先进入 libSystem 调用 libSystem_atfork_prepare() 处理注册的 hooks,接下来如果是动态库就走 dyld 的 _dyld_fork_child() 方法,静态库就不走 dyld 了。(我找到了函数实现但是没有找到判断与调用的地方。)
在 dyld 43 版本还有对静态库的处理 _dyld_fork_parent() 但是最新的版本(655.1.1)已经只剩下 _dyld_fork_child() 了。
// Libsystem-1252.250.1
// init.c()
static const struct _libc_functions libc_funcs = {
.version = 1,
.atfork_prepare = libSystem_atfork_prepare,
.atfork_parent = libSystem_atfork_parent,
.atfork_child = libSystem_atfork_child,
};
接下来 libSystem, dyld 和 xnu 会有一系列复杂的互相调用。《Mac OS X Internals》书中介绍的版本比较旧,新的代码和书中所说的稍有不同,但是原理是差不多的。这一部分直接阅读源码比较困难,所以我选择放弃,直接阅读书里的结论就好。XD
大家可以到这里参考原文
void
libSystem_atfork_child(void)
{
// first call hardwired fork child handlers for Libsystem components
// in the order of library initalization above
_dyld_fork_child();
_pthread_atfork_child();
_mach_fork_child();
_malloc_fork_child();
_libc_fork_child(); // _arc4_fork_child calls malloc
dispatch_atfork_child();
#if defined(HAVE_SYSTEM_CORESERVICES)
_libcoreservices_fork_child();
#endif
_asl_fork_child();
_notify_fork_child();
xpc_atfork_child();
_libtrace_fork_child();
_libSC_info_fork_child();
// second call client parent handlers registered with pthread_atfork()
_pthread_atfork_child_handlers();
}
1.1.2 内核空间的实现
用户空间准备完了就开始进入内核的 fork() 函数了,实现在 bsd/kern/kern_fork.c:
int fork(proc_t parent_proc, __unused struct fork_args *uap, int32_t *retval)
返回值 0 为成功,其他就是错误码。
第一个参数 parent_proc 就是调用 fork 的那个 process,第二个参数 uap 已经弃置不用了,第三个参数就是返回的 pid。父进程会收到 hardcoded 的 0。
关键实现在 fork1() 函数:
int
fork1(proc_t parent_proc, thread_t *child_threadp, int kind, coalition_t *coalitions)
这个函数上来先取父进程的 thread 和 uthread,接着取当前用户 ID kauth_getruid(),也就是我们通过 ps 看到的当前进程由哪个用户创建的信息,我们在 shell 里经常需要 sudo 也就是切换成 root 身份来跑一个进程,这个权限就是通过 kauth 模块管理。
接下来判断当前进程数是否超限,没问题就继续。
count = chgproccnt(uid, 1);
这里把当前用户进程数 + 1,我想到内核启动的时候,也 hardcode 了一句 + 1 给 launchd 这个进程。接着会判断用户的进程数上限是否超限。
接下来是安全检查,判断当前用户是否有权限 fork 新的进程,没问题就开始 switch kind 了,一共有三种类型:
/* process creation arguments */
#define PROC_CREATE_FORK 0 /* independent child (running) */
#define PROC_CREATE_SPAWN 1 /* independent child (suspended) */
#define PROC_CREATE_VFORK 2 /* child borrows context */
其中 vfork() 是 fork() 的变种,大部分 Unix-like 系统都有这两种 fork,区别是 vfork 创建的子进程会 block 住父进程,一直等到子进程跑完 exit 然后父进程才会继续,fork 则不会,可自行编译运行我们上文的小 demo。
至于 spawn 则是给 posix_spawn() 用的,跟 fork() 类似,但是 fork 会继承(或者说复制)父进程的很多资源比如内存,而 spawn 不会。可以参考 Linxu 关于 POSIX Spawn 的文档,简单理解为是给那些性能比较低的设备(比如嵌入式设备)用的。
我们继续看 fork():
cloneproc()// 创建新的 Mach Task (task_t), Unix Process (proc_t) 以及 thread_forkproc()- 主要作用是创建一个新的
proc_t然后把父进程的信息都塞给他 - 查找可用的
pid然后赋值给新的proc_t - 这里参数
inherit_memory如果为true,则vm_map也会 fork 一份,否则就是重新创建一个vm_map然后赋值。fork()进来的为true,posix_spawn()为false。
- 主要作用是创建一个新的
fork_create_child()创建新的线程thread_tprocdup()这个在书中有提但是新版内核已去掉
thread_dup()machine_thread_dup()不同的架构各有实现,主要是复制了当前线程的寄存器信息,FPU 信息等硬件相关的上下文信息。
task_clear_return_wait()thread_wakeup()thread_wakeup_with_result()``` #define thread_wakeup_with_result(x, z) \ thread_wakeup_prim((x), FALSE, (z)) ```thread_wakeup_prim()
书中曰最终会进入 thread_resume() 但是我又没找到从哪里进入的🤦♂️。
1.2 execve()
实现在 bsd/kern/kern_exec.c,我们来个示例代码看看:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
#include <errno.h>
#include <sys/wait.h>
int main() {
pid_t pid;
int status, died;
pid = fork();
if (pid == 0) {
printf("%s\n", "parent");
} else {
int ret = execve("/bin/date",0,0);
printf("%d\n", ret);
}
}
输出如下:
➜ ./a.out
parent
Wed Nov 6 18:55:45 CST 2019
可以看到子进程已经被 /bin/date 覆盖了。同样的,这个函数也有用户空间和内核空间实现,上面示例我们用的接口是 POSIX 定义的:
int execve(const char * __file, char * const * __argv, char * const * __envp);
接受文件路径参数,参数列表和环境参数。
到了内核这个函数则是:
// bsd/kern/kern_exec.c
int
execve(proc_t p, struct execve_args *uap, int32_t *retval)
p 是当前进程,uap 是用户空间传过来的参数,有三个:
uap->fname文件名uap->argp参数列表uap->envp环境参数
对应用户空间里我们传的三个参数。最后 retval 是给上层的返回值,函数自身返回 0 则成功。
该函数的主要实现在 __mac_execve()。
先组装一个 image_params 数据结构:
struct image_params {
user_addr_t ip_user_fname; /* argument */
user_addr_t ip_user_argv; /* argument */
user_addr_t ip_user_envv; /* argument */
int ip_seg; /* segment for arguments */
struct vnode *ip_vp; /* file */
struct vnode_attr *ip_vattr; /* run file attributes */
struct vnode_attr *ip_origvattr; /* invocation file attributes */
cpu_type_t ip_origcputype; /* cputype of invocation file */
cpu_subtype_t ip_origcpusubtype; /* subtype of invocation file */
char *ip_vdata; /* file data (up to one page) */
int ip_flags; /* image flags */
int ip_argc; /* argument count */
int ip_envc; /* environment count */
int ip_applec; /* apple vector count */
char *ip_startargv; /* argument vector beginning */
char *ip_endargv; /* end of argv/start of envv */
char *ip_endenvv; /* end of envv/start of applev */
char *ip_strings; /* base address for strings */
char *ip_strendp; /* current end pointer */
int ip_argspace; /* remaining space of NCARGS limit (argv+envv) */
int ip_strspace; /* remaining total string space */
user_size_t ip_arch_offset; /* subfile offset in ip_vp */
user_size_t ip_arch_size; /* subfile length in ip_vp */
char ip_interp_buffer[IMG_SHSIZE]; /* interpreter buffer space */
int ip_interp_sugid_fd; /* fd for sugid script */
/* Next two fields are for support of architecture translation... */
struct vfs_context *ip_vfs_context; /* VFS context */
struct nameidata *ip_ndp; /* current nameidata */
thread_t ip_new_thread; /* thread for spawn/vfork */
struct label *ip_execlabelp; /* label of the executable */
struct label *ip_scriptlabelp; /* label of the script */
struct vnode *ip_scriptvp; /* script */
unsigned int ip_csflags; /* code signing flags */
int ip_mac_return; /* return code from mac policy checks */
void *ip_px_sa;
void *ip_px_sfa;
void *ip_px_spa;
void *ip_px_smpx; /* MAC-specific spawn attrs. */
void *ip_px_persona; /* persona args */
void *ip_cs_error; /* codesigning error reason */
uint64_t ip_dyld_fsid;
uint64_t ip_dyld_fsobjid;
};
组装完了之后就 active 一下 image:
static int
exec_activate_image(struct image_params *imgp)
这个函数主要是分配内存,权限检查,通过 namei() 方法找到该二进制文件,使用 vn 接口(跟文件系统无关的抽象接口)读取文件头,最多读一页。
error = vn_rdwr(UIO_READ, imgp->ip_vp, imgp->ip_vdata, PAGE_SIZE, 0,
UIO_SYSSPACE, IO_NODELOCKED,
vfs_context_ucred(imgp->ip_vfs_context),
&resid, vfs_context_proc(imgp->ip_vfs_context));
读到文件头信息之后再循环走一遍,判断是否如下三种:
{ exec_mach_imgact, "Mach-o Binary" }, // 普通的单架构 Mach-o 二进制文件
{ exec_fat_imgact, "Fat Binary" }, // 多架构 Mach-o 二进制文件
{ exec_shell_imgact, "Interpreter Script" }, // 脚本
找到了就使用对应 imgact 转成函数指针然后调用它,传入 imgp 参数。
error = (*execsw[i].ex_imgact)(imgp);
我们直接看 exec_mach_imgact():
static int
exec_mach_imgact(struct image_params *imgp)
这个函数最重要的地方是:
lret = load_machfile(imgp, mach_header, thread, &map, &load_result);
load_machfile() 实现在 bsd/kern/mach_loader.c 里面。负责分配物理内存和虚拟内存,如果有 ASLR (就是内存 offset 加个随机偏移,默认开)就随机一下,然后解析 Mach-o 文件,根据 Mach-o 文件的 load commands 信息把二进制数据装进内存。
其中用到了 parse_machfile() 方法处理 Mach-o 文件里的 load commands。我们知道有了 ASLR 之后大家的入口都从 LC_UNIXTHREAD 变成了 LC_MAIN。这个方法就把这些信息都保存到 load_result_t 里面然后返回, load_result_t 里包含了 threadstate,里面就有 entry_point 信息。
load mach file 结束后 activate_exec_state()
static int
activate_exec_state(task_t task, proc_t p, thread_t thread, load_result_t *result)
这个函数会调用 thread_setentrypoint() 把之前函数入口 entry_point 地址塞进 eip 寄存器于是函数就愉快地被调用了。
thread_setentrypoint(thread, result->entry_point);
// i386 实现
#define CAST_DOWN_EXPLICIT( type, addr ) ( ((type)((uintptr_t) (addr))) )
/*
* thread_setentrypoint:
*
* Sets the user PC into the machine
* dependent thread state info.
*/
void
thread_setentrypoint(thread_t thread, mach_vm_address_t entry)
{
pal_register_cache_state(thread, DIRTY);
if (thread_is_64bit_addr(thread)) {
x86_saved_state64_t *iss64;
iss64 = USER_REGS64(thread);
iss64->isf.rip = (uint64_t)entry;
} else {
x86_saved_state32_t *iss32;
iss32 = USER_REGS32(thread);
iss32->eip = CAST_DOWN_EXPLICIT(unsigned int, entry);
}
}
这里涉及 i386 架构的寄存器设计,以底下的 32 位为例,eip 就是 PC 寄存器(Program Counter Register)。
#define REG_PC EIP
#define REG_FP EBP
#define REG_SP UESP
#define REG_PS EFL
#define REG_R0 EAX
#define REG_R1 EDX
在 i386 或曰 x86 架构里面,这个寄存器就是下一个指令会访问到的内存地址。于是我们将它设置为函数入口,该函数就开始了。
1.3 LC_MAIN 的 entryoff
有了 ASLR 之后入口地址不再是静态的偏移量而是每次都会随机一下。如果是以前的入口在 LC_UNIXTHREAD 的,这时候取 entry point 就直接赋值。
但是 LC_MAIN 入口的却会传给 LC_LOAD_DYLINKER 段里面指定使用的 dyld。由于 Release App 基本都会去掉 debugging symbol 放进 dSYM,方便起见我们直接看我的 Debug 版的 Just Focus for Mac:
Load command 11
cmd LC_MAIN
cmdsize 24
entryoff 535536
stacksize 0
entryoff 这个偏移量是基于文件初始位置的。
535536 转成 hex 就是 0x000082BF0,再加上 macOS 上的基准地址 0x100000000 就是 0x100082BF0。方便起见我们直接用 MachOView 来看看 (__TEXT,__text) 段里的数据
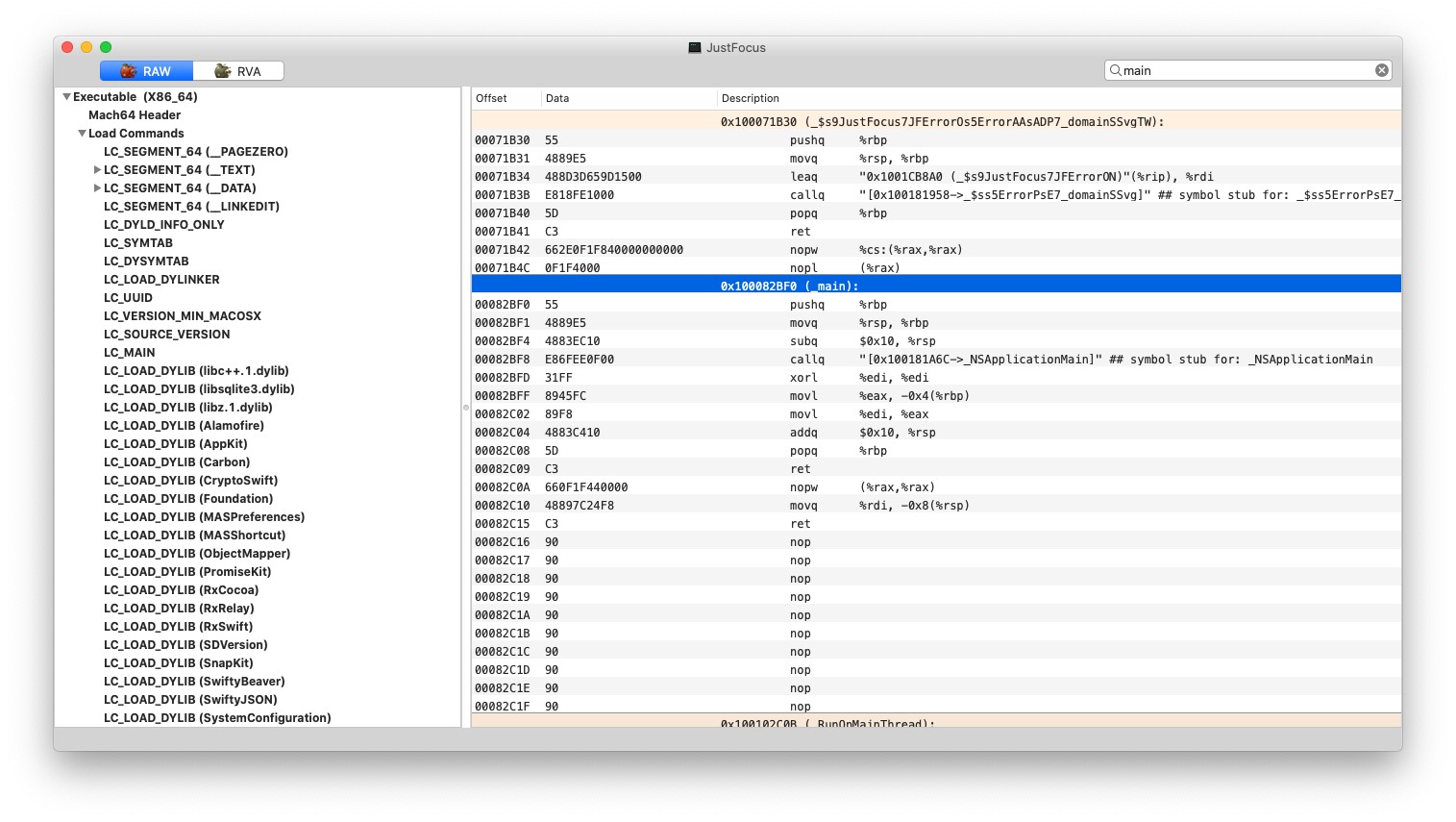
可以看到这里就是我们的 _main() 函数入口。当然这些数值都是静态的,当 App 被加入内存时,内核会计算偏移量所以运行时的地址还得再加上那个偏移量。
接下来 parser_machinefile() 就会去调用 load_dylinker(),初始化一些 dylddata 然后又回去调用 parse_machinefile() 一次。这一次,parse 的不是别人,而是 LC_LOAD_DYLINKER 里指定的 dyld,比如上面的 /usr/lib/dyld。
这个家伙当然不用 LC_MAIN 而是 LC_UNIXTHREAD 啦:
Load command 12
cmd LC_UNIXTHREAD
cmdsize 184
flavor x86_THREAD_STATE64
count x86_THREAD_STATE64_COUNT
rax 0x0000000000000000 rbx 0x0000000000000000 rcx 0x0000000000000000
rdx 0x0000000000000000 rdi 0x0000000000000000 rsi 0x0000000000000000
rbp 0x0000000000000000 rsp 0x0000000000000000 r8 0x0000000000000000
r9 0x0000000000000000 r10 0x0000000000000000 r11 0x0000000000000000
r12 0x0000000000000000 r13 0x0000000000000000 r14 0x0000000000000000
r15 0x0000000000000000 rip 0x0000000000001000
rflags 0x0000000000000000 cs 0x0000000000000000 fs 0x0000000000000000
于是设置好 entry point,通过 dyld 起飞!
二、dyld 如何调用 App 入口
内核的 fork() 和 exec() 任务到给 thread 设置 entry point 之后就结束了。至于为什么往寄存器里塞一个函数指针地址它就开始跑起来,那就涉及到汇编,CPU 如何执行指令了。阮一峰的科普文章《汇编语言入门教程》写得很浅显易懂可以参考一下。
接下来我们切换到 dyld 的源码。dyld 在模拟器和真机上有不同的启动入口:
// configs/dyld.xcconfig
ENTRY[sdk=*simulator*] = -Wl,-e,_start_sim
ENTRY[sdk=iphoneos*] = -Wl,-e,__dyld_start
ENTRY[sdk=macosx*] = -Wl,-e,__dyld_start
入口函数的实现是汇编,在 dyldStartup.s 文件。我们可以搜索关键词 call:
// i386 实现
.text
.align 4, 0x90
.globl __dyld_start
__dyld_start:
popl %edx # edx = mh of app
pushl $0 # push a zero for debugger end of frames marker
movl %esp,%ebp # pointer to base of kernel frame
andl $-16,%esp # force SSE alignment
subl $32,%esp # room for locals and outgoing parameters
call L__dyld_start_picbase
L__dyld_start_picbase:
popl %ebx # set %ebx to runtime value of picbase
movl Lmh-L__dyld_start_picbase(%ebx), %ecx # ecx = prefered load address
movl __dyld_start_static_picbase-L__dyld_start_picbase(%ebx), %eax
subl %eax, %ebx # ebx = slide = L__dyld_start_picbase - [__dyld_start_static_picbase]
addl %ebx, %ecx # ecx = actual load address
# call dyldbootstrap::start(app_mh, argc, argv, slide, dyld_mh, &startGlue)
movl %edx,(%esp) # param1 = app_mh
movl 4(%ebp),%eax
movl %eax,4(%esp) # param2 = argc
lea 8(%ebp),%eax
movl %eax,8(%esp) # param3 = argv
movl %ebx,12(%esp) # param4 = slide
movl %ecx,16(%esp) # param5 = actual load address
lea 28(%esp),%eax
movl %eax,20(%esp) # param6 = &startGlue
call __ZN13dyldbootstrap5startEPK12macho_headeriPPKclS2_Pm
movl 28(%esp),%edx
cmpl $0,%edx
jne Lnew
# clean up stack and jump to "start" in main executable
movl %ebp,%esp # restore the unaligned stack pointer
addl $4,%esp # remove debugger end frame marker
movl $0,%ebp # restore ebp back to zero
jmp *%eax # jump to the entry point
# LC_MAIN case, set up stack for call to main()
Lnew: movl 4(%ebp),%ebx
movl %ebx,(%esp) # main param1 = argc
leal 8(%ebp),%ecx
movl %ecx,4(%esp) # main param2 = argv
leal 0x4(%ecx,%ebx,4),%ebx
movl %ebx,8(%esp) # main param3 = env
所以在我们的 App 的函数入口被调用之前,dyldbootstrap::start(app_mh, argc, argv, slide, dyld_mh, &startGlue)函数会先被调用,它的返回值是真正 App 的函数入口,比如说 main()。
uintptr_t start(const struct macho_header* appsMachHeader, int argc, const char* argv[],
intptr_t slide, const struct macho_header* dyldsMachHeader,
uintptr_t* startGlue)
这个函数调用了 dyld::_main() 这个函数才是重点,上面不同架构的汇编都会进这里,只是参数各有不同。这个函数会 load 所有的动态库 image,初始化,最后再拿到真正的 App 入口,然后返回。最后汇编代码里就会 jmp 到 App 入口,于是 App 就愉快地启动了。
三、launchd
如果你在 Activity Monitor App 里选中一个进程,点左上角的感叹号,你可以看到当前进程的 Parent Process。然后你就会发现基本上所有你通过 Finder, Launchpad 之类的方式启动的 App(命令行的 open 也是),它们的 parent process 都是 launchd (当然 App 自行创建的子进程就不是,比如 Google Chrome Helper)。在 iOS 的 Crash Log 里,App 的 parent process 也是 launchd。
在 macOS 上我们可以使用系统提供的 Launch Service 来启动其他 App,最终也是由 launchd 来完成 fork() 和 execve()。
launchd 的 parent process 是 kernel_task。kernel_task 进程就是内核进程本程了,在内核启动时自行创建,实现在 bsd/kern/bsd_init.c 的 bsd_init(void) 函数。
launchd 是 Mac OS X Tiger 10.4 开始引入的特性,在 Kernel 启动时创建,然后它负责创建其他系统守护进程(Daemons),也负责创建系统登录界面。
还有另一个服务是 launchctl,可以跟 launchd 进行 IPC 通信,经常被用来做开机启动任务。LaunchControl.app 就是非常好的 launchctl/launchd 图形界面。
四、小结
Unix 的 fork() 和 execve() 方法在上学的时候学校曾经教过。但是一则当时的讲解还比较偏高级抽象,二则年代久远已经记不太清了,所以回顾学习这一段的时候还是费了点力气去了解诸如汇编、寄存器之类的概念。Apple 开源的代码还是很多的,除了内核,大量的系统服务也都开源了,非常有助学习。最近学习内核代码,一边看代码一边跟着书本理解,总让我有一种“源码在手,天下我有”的错觉。XD
内核系列文章
- macOS 内核之一个 App 如何运行起来
- macOS 内核之网络信息抓包(三)
- macOS 内核之网络信息抓包(二)
- macOS 内核之网络信息抓包(一)
- macOS 内核之系统如何启动?
- macOS 内核之内存占用信息
- macOS 内核之 CPU 占用率信息
- macOS 内核之 hw.epoch 是个什么东西?
- macOS 内核之从 I/O Kit 电量管理开始