
今天在中文世界我们处理文本文件一般都采用UTF-8编码,但这是1993年Unicode标准出来以后,才随着互联网兴起而流行起来。所以我们在处理一些“老旧”系统的时候难免还是会遇到不同编码的文本文件,比如从某银行下载的账单就经常以意想不到的编码方式出现。
这时候直接对裸数据进行读取会失败,为了让整个流程更自动化一些,我们需要针对这些文件进行转码处理。
一、检测当前文本文件的编码
除了Unicode以外,世界上还存在非常多种不同的编码,仅汉字就有BIG5, GB,GBK,GB 2312等等。Google提供的ICU(International Components for Unicode)项目可以很好地帮我们找出当前文本最可能的编码格式。ICU项目应用广泛,Apache也用了,不过这个库比较大,Google还有一个简化版的库: compact_enc_det 也做了类似的事情。
输入文本bytes,库内部会循环多次进行匹配,匹配出来分数高的就是最可能的文本编码。为了优化效率,compact_enc_det 会先扫描前 16KB 的bytes,然后针对接下来最多 256KB 的bytes,之检测高于 0x80 的编码,以提高检测效率。这个库一共能检测出75种不同的文本编码。
另外针对我们最常用的UTF-8编码,还需要对文件头进行BOM处理。
BOM是Byte order mark的缩写,在Unicode标准出来以前,大家会在一个文本文件的开头写入16位的数据,用来表示当前文本的编码和大小端。
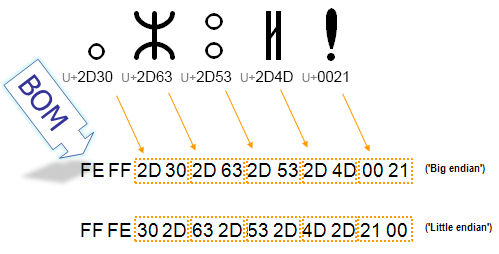
比如上图就是UTF-8文件头的BOM。在Web浏览器中,HTML的BOM一般是必须的,但是更好的做法是我们在HTML的Meta标签中写明当前文件的Encoding。
所以遇到此类带BOM的文件,我们在解码的时候需要先去掉BOM,再编码时还要记得写回BOM。
二、进行编码转换
NodeJS这个库bnoordhuis/node-iconv采用C语言实现了一个iconv方法。
index.js部分只是接口封装,核心逻辑在 binding.c 里面。
//JS入口
const conv = bindings.make(fixEncoding(fromEncoding),
fixEncoding(toEncoding));
//对应C的make()函数
conv = iconv_open(to, from);
这里具体实现引入了 iconv_open1.h 和 iconv_open2.h,应该是使用了libconv里的代码,我们主要关注unicode的loope convert方法:
static size_t unicode_loop_convert (iconv_t icd,
const char* * inbuf, size_t *inbytesleft,
char* * outbuf, size_t *outbytesleft)
其中最关键的是 incount = cd->ifuncs.xxx_mbtowc(cd,&wc,inptr,inleft);,因为UTF-8是一种可变宽度的编码,所以一次循环要读入多个bytes才能决定是否合成一个完整的Unicdoe字符。
作者把不同编码的转换函数都统一到mbtowc(),我们可以从 encodings.def 里找到 UTF-8 的对应函数:
DEFENCODING(( "UTF-8", /* IANA, RFC 2279 */
/*"UTF8", JDK 1.1 */
/*"CP65001", Windows */
),
utf8,
{ utf8_mbtowc, NULL }, { utf8_wctomb, NULL })
其实现根据 RFC 3629 规范来:
static int
utf8_mbtowc (conv_t conv, ucs4_t *pwc, const unsigned char *s, size_t n)
里面就有一大堆的if-else实现了该规范。我们查表可知,UTF-8主要分为四个区域:
Char. number range | UTF-8 octet sequence
(hexadecimal) | (binary)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
0x0000-0x007F: ASCII字符0x0080-0x07FF: 带符号的拉丁文、希腊文等字符0x0800-0xFFFF: 大部份常用字,比如汉字。这也是为什么有些当前文本是否中文的正则判断会直接判断这个区间。- 剩下的就是很少使用的辅助平面(Plane),放各种奇怪的符号、古老语言、表情等等。
utf8_mbtowc()会根据该规范读入相应长度的字节,返回给上层解出来的字节长度。上述四个区间,每个区间只有一种编码方式,如第一个区间,0x0000-0x007F 以下就是 1 个 byte,对应ASCII。
如果落入第二区间0x0080-0x07FF,就要看高位的bit,110开头的就填入110xxxxx,10开头的就填入10xxxxxx。每一个子区间都是固定的。
三、看来实现一个iconv也不是那么简单
本文以UTF-8编码为例,简述了如何检测纯文本的编码以及如何做编码转换。可以看到UTF-8还是相对简单的编码规范,已经具备一定工作量。如果要自己写一个iconv的话,支持75种以上的编码,工作量可想而知。
参考资料
- The byte-order mark (BOM) in HTML
- Byte order mark - Wikipedia
- UTF-8 - Wikipedia
- svn.apache.org/repos/asf/tika/tags/1.3/tika-parsers/src/main/java/org/apache/tika/parser/txt/CharsetDetector.java
- ICU - International Components for Unicode
- google/compact_enc_det: compact_enc_det - Compact Encoding Detection
- RFC 3629 - UTF-8, a transformation format of ISO 10646