

一、PAC
前两天同事提到苹果去年发布的 A12 芯片支持 arm64e 指令集,提供了指令地址加密功能。说是虽然系统是 64 位的,但是 arm64 指令地址根本用不满,所以把高位的部分(upper bits)拿来存一个指针地址签名。
当时我就很好奇,现在 arm64 的内存指针都是 64 位的,为啥会用不满?于是我学习了一下 ARMv8.3 新增的 PAC 功能。
首先我们来看看 PAC 是啥。PAC 是 Pointer Authentication Code 的缩写,字面意思翻译就是指针验证码。在 CPU 执行指令前的时候先拿指针的高位签名跟低位的实际地址部分做一下校验,如果失败了就直接抛出异常,从而防止指令地址被篡改。
Exception Subtype: KERN_INVALID_ADDRESS at 0x0040000105394398 -> 0x0000000105394398 (possible pointer authentication failure)
为了实现这个 PAC 功能,arm64e 新增了两个指令:
PACIASP计算 PAC 加密并加到指针地址上AUTIASP校验加密部分,并还原指针地址
二、PAC 应用举例
并不是所有的指针都需要 PAC 保护。高通的 ARMv8.3文档给这项新技术举了个例子:
| 行为 | 没有栈保护 | 使用 PAC |
|---|---|---|
| 函数入栈(入口) | SUB sp, sp, #0x40 STP x29, x30, [sp,#0x30] ADD x29, sp, #0x30 … |
PACIASP SUB sp, sp, #0x40 STP x29, x30, [sp,#0x30] ADD x29, sp, #0x30 … |
| 函数出栈(返回) | ... LDP x29,x30,[sp,#0x30] ADD sp,sp,#0x40 RET |
... LDP x29,x30,[sp,#0x30] ADD sp,sp,#0x40 AUTIASP RET |
把函数返回地址加密,用于对抗缓冲区溢出攻击(buffer-overflow vulner-ability)。
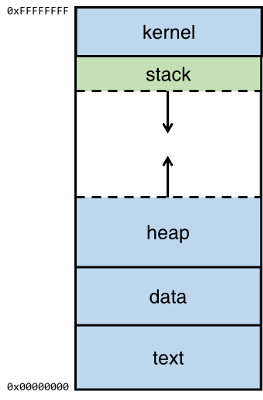
简单介绍一下缓冲区溢出攻击,上图是一个 App 在内存时的布局(memory layout),在这个 case 中,我们只关注其中的 stack 和 heap。
heap 也就是堆,堆会往上长,stack 也就是栈,往下长。这项攻击利用的就是 stack 的缓冲区增长过程中的漏洞。
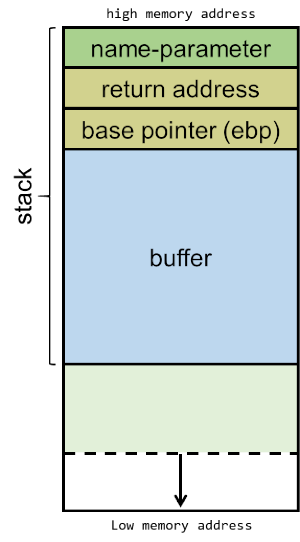
一个函数被调用的时候需要在 stack 上入栈很多东西,从内存高位开始,参数名,函数的返回地址,接下来是函数内部要执行的指令。这样当指令执行完就一个个出栈,到了函数返回地址 CPU 就知道该往哪里去了。
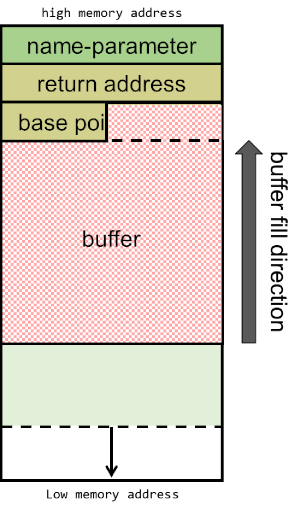
可以看到栈底的东西是用来控制 CPU 指令往哪里跳的,而我们代码里分配的 buffer 跟它连在一起。关键点在于 buffer 的填充方向是从低位往高位去的。如果我们先分配一小块 buffer,然后往里面写一段超出 buffer 长度的数据,我们就能直接改变栈顶的数据,比如我们的目标:return address。
雪城大学有一个教程教你怎么利用 fwrite 写一段超过 buffer 长度的数据,然后把准备好的调起 shell 的函数入口塞进去替换到原先的函数返回地址,这样 CPU 执行完写 buffer 指令后就拿到该函数地址,直接出栈打开了 /bin/bash。
我们的程序是由内核运行在用户空间的,默认没有 root 权限。但是当内核执行我们修改过的返回地址打开 /bin/bash 的时候,就是以内核权限打开的。这时候我们就获得了一个有 root 权限的 shell,接下来想干啥就可以干啥了。
有了 PAC 之后,我们编译的 App 就可以带上这个保护,遇到这种篡改过的地址就直接抛出异常。当然这个例子里的攻击很简单,操作系统早就有了多种防范手段,这里只是举一个 PAC 应用的例子。而 PAC 是在 CPU 指令层面加入的保护,理论上只是多耗了一个 CPU 周期而已,性能应该要比在软件层面的保护高得多。
三、为什么 arm64 的指针地址没有用满 64 位?
PAC 介绍完了,接下来我们来看看为什么指针地址用不满,还剩一半可以直接用来存 PAC 签名?
翻了苹果的文档,高通的文档都只是轻描淡写地说利用没有用到的高位。
于是我们开脑洞想是不是一个 Mach-O 文件的 (__TEXT,__text) 段(机器码段)最大不能超过 4GB (一个 32 位指针的最大地址),又或者是整个操作系统能够跑起来的所有进程加起来不能超过 4GB 之类的。
但是其实 __text 段里的数据全都是只读的,内核随时可以换出(page out),需要的时候再换入(page in),如果忽略 vm_pressure 的话,理论上应该只要它不要超过虚拟内存大小就行(不可能有人写那么大的代码的)。最后推断其实现在的 App 根本用不了那么多的地址空间。因为用不了那么多,所以才可以利用起高位。
不过这些脑洞都没有道理,其实正确答案是: 系统虚拟内存的寻址设计根本不需要用满 64 位指针。
我们看 AARch64 Linux 的虚拟内存分级设计。一个内存页大小为 4KB,整个虚拟内存被划分为 3 级或 4 级(level),下面我们以 3 级为例。
Start End Size Use
-----------------------------------------------------------------------
0000000000000000 0000007fffffffff 512GB user
ffffff8000000000 ffffffffffffffff 512GB kernel
用户空间的地址把 63:48 位都置为 0,内核空间则都置为 1。
Translation table lookup with 4KB pages:
+--------+--------+--------+--------+--------+--------+--------+--------+
|63 56|55 48|47 40|39 32|31 24|23 16|15 8|7 0|
+--------+--------+--------+--------+--------+--------+--------+--------+
| | | | | |
| | | | | v
| | | | | [11:0] in-page offset
| | | | +-> [20:12] L3 index
| | | +-----------> [29:21] L2 index
| | +---------------------> [38:30] L1 index
| +-------------------------------> [47:39] L0 index
+-------------------------------------------------> [63] TTBR0/1
这样只需要 L1 + L2 + L3 + in-page offset 就能定位到一个虚拟内存地址。在 AARch64 Linux 的设计里,一个用户空间的内存指针其实只需要用到 0:47 一共 48 位,剩下的就都是没用到的了(是不是回想起大学时计算机课的内容了😂)。
那么 PAC 引入之后剩下的位是怎么利用的呢?参考高通的这份文档,分为两种情况:
- 指针有标记位
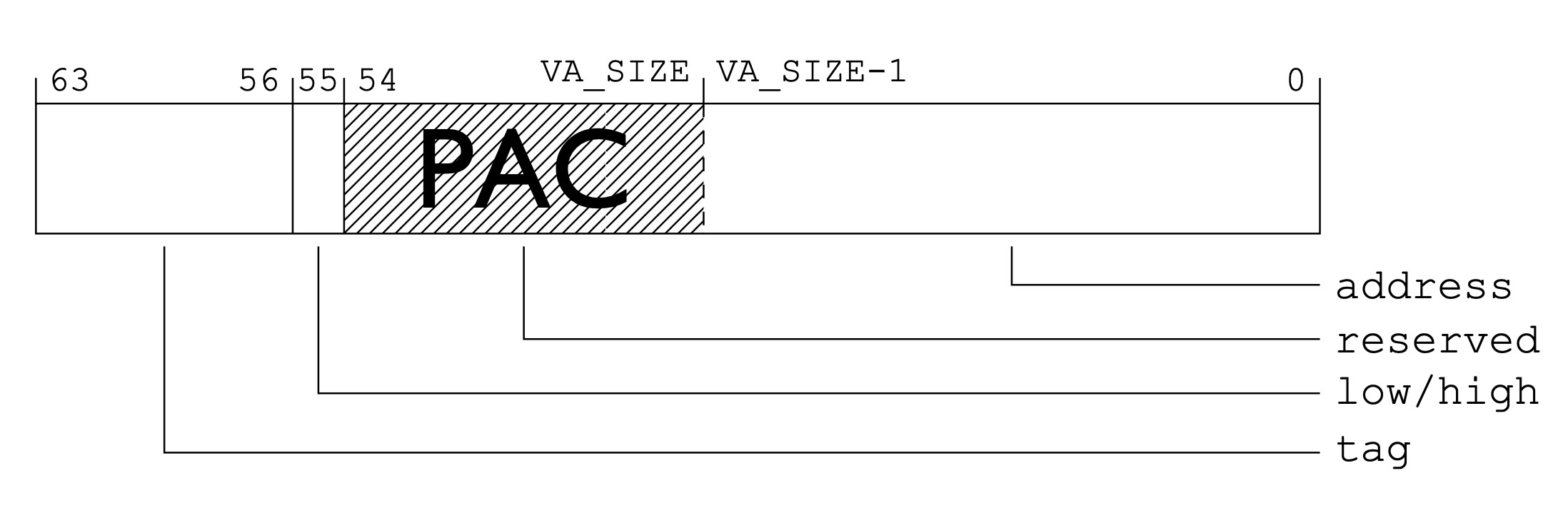
有标记位的情况下因为高位部分可能已经被用来存储额外的指针标记了,所以只用了
48:54一共 7 位来存储。 -
指针没有标记位
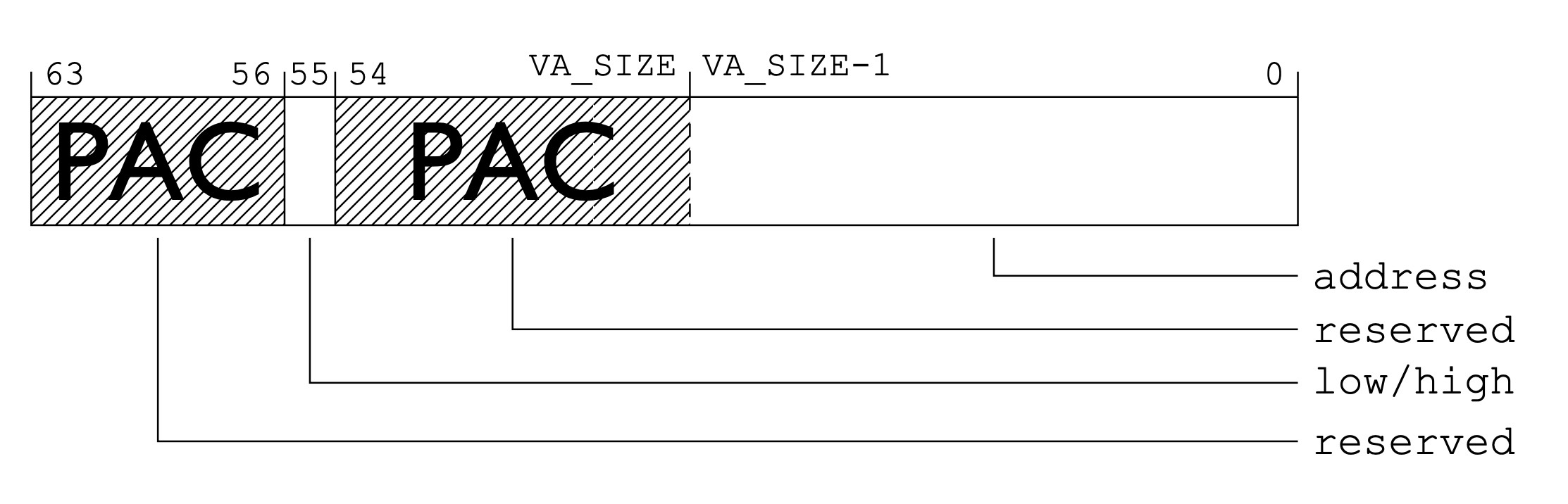
没有标记位的情况就往
63:56写入 8 位,往48:54写入 7 位,一共用了 15 位。
Tagged pointer其实用法很多,本质上跟 PAC 的原理是一样的,都是利用了指针的剩余无效空间。比如苹果在 iOS 7 引入的 NSTaggedPointer,利用指针的剩余空间来存数据的值。比如一个 NSString 如果内容很短,就可以利用指针剩余的 bits 把内容存起来,不需要另外开辟一个内存空间。
高通的文档里如果用上了 15 位那可能剩下的空间就不够 NSTaggedPointer 发挥了,所以如果要对这类指针用 PAC 就只能用 7 位签名。当然一般这些数据应该不需要保护就是了。
参考资料
- Preparing Your App to Work with Pointer Authentication | Apple Developer Documentation
- Pointer Authentication on ARMv8.3 - Qualcomm https://www.qualcomm.com › media › documents › files › whitepaper-poi...
- 什么是缓冲区溢出攻击? - 知乎
- Buffer Overflow Vulnerability Lab - Computer and Information ... www.cis.syr.edu › ~wedu › seed › Labs › Vulnerability › Buffer_Overflow
- Buffer overflow attacks explained
- Documentation/arm64/memory.txt (v4.11) [LWN.net]
- Tagged pointer - Wikipedia
- mikeash.com: Friday Q&A 2012-07-27: Let's Build Tagged Pointers